
The API as Archivist
The archive translates well. The archivist doesn't come with it.


An audit of 800 records from the National Archives Catalog finds that machine interfaces preserve archival structure with unexpected fidelity — but expose a deeper problem: the context that survives is inherited, not descriptive, and the difference matters enormously.
Archivists have spent decades building descriptive systems that help researchers understand records within their proper context. Increasingly, however, researchers are not the only consumers of archival collections. APIs, retrieval systems, large language models, and autonomous agents are beginning to interact directly with archival repositories, often without ever encountering a reference archivist, collection guide, or traditional finding aid.
This shift raises a question that archival theory has only recently begun to confront. When archives are consumed through APIs rather than reading rooms, how much archival context survives?
The concern is understandable. Archival description is fundamentally contextual. Records derive meaning from provenance, original order, custodial history, relationships to other records, and the descriptive work archivists perform over decades. APIs appear to reduce archives to structured data — objects, fields, and relationships. From a distance, it seems reasonable to assume that machine interfaces flatten archives into databases and strip away much of the contextual infrastructure that archivists have spent generations constructing.
To test that assumption, I audited 800 records retrieved through the National Archives Catalog API across eight subject areas: Revolutionary War pensions, Revolutionary War widow pensions, Japanese American internment records, NSDAP membership records, born-digital federal records, audiovisual records, federal datasets, and federal email records. The objective was not to evaluate search performance or retrieval effectiveness. It was to examine whether the contextual structures archivists consider essential remain visible when records are encountered through a machine-readable interface.
The results were more complicated than the prevailing assumption suggests — in both directions.
What the audit measured
Each record was evaluated against twelve dimensions of contextual survival: identifiers, titles, provenance information, hierarchical placement, record group context, descriptive content, chronology, access restrictions, relationship context, digital object presence, evidence of physical transformation history, and machine-accessible structure.
The scoring model was not intended as a formal archival standard. It served as a heuristic for assessing how much contextual information remains available when records are accessed programmatically. The underlying question was straightforward: if a researcher or AI system interacts only with the API, how much of the archival framework surrounding a record remains visible?

The structural context survives
The prevailing assumption among many archivists is that APIs strip away context. The audit suggests a more complicated reality. Across all 800 records, ten of the twelve scored dimensions appeared in every single record. Identifiers, titles, hierarchical placement, record group structures, provenance indicators, access and use restriction information, digital object references, physical transformation history, and relationship context all appeared at or near 100 percent.

This finding is significant because it suggests that the API is not simply exposing isolated records detached from their archival environment. Much of the structural framework archivists create and maintain remains visible through machine access. Provenance indicators survive — not as standalone fields, but as part of the ancestor chain that the API returns alongside each record. Hierarchical relationships survive. Record group context survives in 78 percent of records. In many cases, the API preserves enough information for a machine to determine where a record belongs within a broader archival structure.
The implication is that archival context may be more resilient in machine-readable environments than many archivists assume. The API does not eliminate archival structure. Instead, it translates substantial portions of that structure into a form that software systems can consume directly.
The inherited context problem
The structural picture is real, but requires a critical qualification that the aggregate numbers obscure. Much of what appears to survive contextual translation is not present at the item level at all. It is inherited.
Consider chronology. Every one of the 800 sampled records returned date information — a result that sounds encouraging. But not a single record carried its own date field. Every date in the dataset arrived via ancestor records: the series, the record group, the collection. The API returns these ancestors alongside the primary record, and a naive reading of the response suggests that chronological context is universally present. A more careful reading reveals that what is present is the collection’s date range, not the item’s. A pension file item dated to a specific pension application year cannot be distinguished from the collection’s 1800–1900 span without the narrative description that explains the difference. For 77 percent of the sample, that description does not exist.
None of the 800 sampled records carried an item-level date field. All chronological information was inherited from ancestor records — series and record group date ranges that describe the collection, not the item.
A machine reading the API response cannot distinguish between a collection date range and an item date without a narrative description. In 77 percent of records, that description is absent.
Provenance presents the same structure. Creators appear at 100 percent — but again, universally via ancestor records. The creator field typically identifies the agency that created the series or record group, not necessarily the specific organizational unit responsible for the individual document. The distinction matters when an agency reorganized repeatedly over decades, or when multiple sub-units contributed to a single series. The API surfaces a creator. It does not always surface the right one at the right level of specificity.
This is a subtle but important finding. The API is not stripping context. It is faithfully returning what the catalog contains. The catalog reflects descriptive decisions made by archivists over decades, many of whom applied description primarily at the series and record group level and left item-level records relatively bare. The API exposes those decisions with perfect fidelity. What looks like an API problem is often a description problem that predates the API by generations.
Narrative description: where the gaps are real and uneven
The most significant gap in contextual survival is narrative description — scope notes, content notes, and administrative histories that explain what records are, how they were created, and how they should be interpreted. Only 22.9 percent of sampled records carried any descriptive content.
That aggregate masks a distribution that should concern archivists far more than the overall figure suggests.
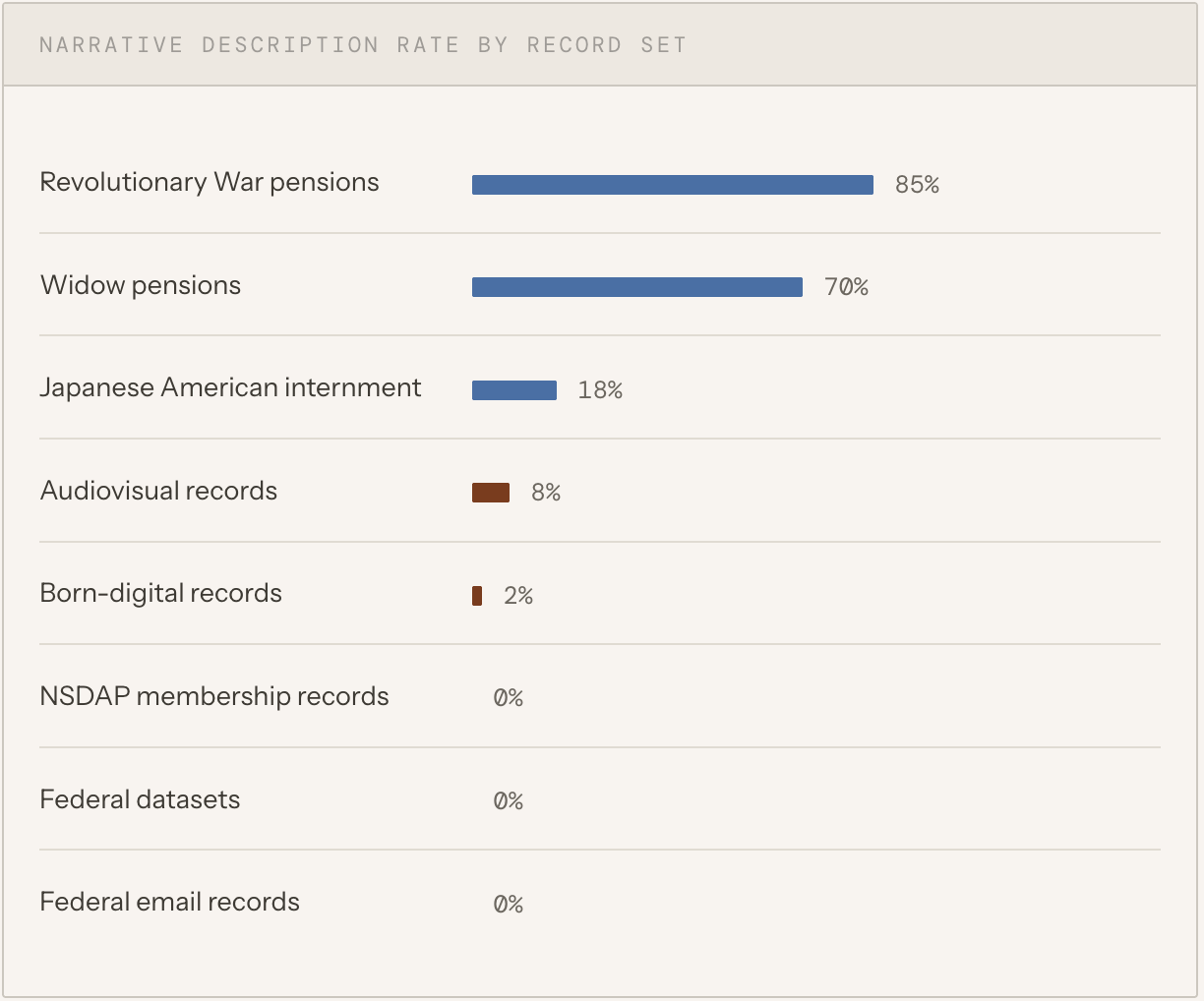
Revolutionary War pension records and widow pension records — collections that have received sustained archival attention over more than a century — carried descriptions in 85 percent and 70 percent of sampled records, respectively. These are among the most heavily used genealogical collections in the federal government, and that use has driven description.
Everything else told a different story. Internment records: 18 percent. Audiovisual: 8 percent. Born-digital: 2 percent. NSDAP membership records, federal datasets, and federal email records: zero.
The implication is not that the API is failing these collections. The API is returning what exists. The implication is that description investment has followed researcher demand — and that collections where demand is lower, more specialized, or more recent have received less descriptive attention dramatically. As AI systems begin treating all collections as equally accessible via API, they will encounter wildly uneven interpretive infrastructure. Well-described collections will appear rich. Underdescribed collections will appear structurally coherent but interpretively empty.
The NSDAP case
The NSDAP membership records illustrate the problem in its most concentrated form. These records averaged 10.98 out of 12 on structural dimensions. Identifiers, hierarchical placement, ancestor provenance, ancestor dates, access conditions, and digital object references all appeared consistently. A machine retrieving these records through the API encounters a well-organized, structurally coherent object.
The machine does not encounter any explanatory text. Descriptive content appeared in zero of the 100 sampled records. The creator information that does appear arrives at the record group level — Department of State, series dates spanning 1940 to 2002 — without explaining the custodial history that brought NSDAP membership documentation into State Department holdings, the legal framework under which it was released, or the limitations researchers should observe when interpreting records that were themselves created as instruments of bureaucratic persecution.
NSDAP records scored 10.98/12 on structural dimensions. Narrative description: 0 of 100 records. A machine can place these records in their archival hierarchy and retrieve associated digital objects. It cannot recover the explanatory context that tells a researcher — or an AI — what the records actually are.
This creates an unusual situation. Modern AI systems are exceptionally good at working with structure. They can navigate hierarchies, follow relationships, aggregate metadata, and synthesize information across large record sets. The NSDAP records give them plenty to work with structurally. What they cannot recover is the interpretive layer — the provenance narrative, the custodial explanation, the researcher guidance — that archivists have not yet supplied at the item level, and that the API has no mechanism to fabricate.
When the API becomes the intermediary
Historically, archivists served as intermediaries between researchers and records. Reference interviews, collection guides, descriptive essays, and institutional knowledge supplied context alongside retrieval. Researchers did not simply receive records. They received records accompanied by an explanation.
Machine access changes that relationship. Increasingly, records are encountered through software systems that retrieve metadata directly from APIs. In that environment, the API begins to assume some of the functions traditionally associated with archival description. It identifies records, exposes relationships, communicates hierarchy, and provides access pathways. In practical terms, it becomes a new kind of intermediary between users and archival collections — one that was not designed for the role, does not know it occupies it, and carries no professional obligation to the researchers it serves.
The audit suggests that APIs perform some of these functions remarkably well. Structural context appears surprisingly durable. But the API’s intermediary role breaks down precisely where archival expertise has historically mattered most: at the point where a researcher needs to understand not just where a record sits, but what it means, how it came to exist, and what its limitations are as evidence.
The API cannot supply that context if archivists never created it. And for large portions of the federal archival record — born-digital materials, email, audiovisual collections, records of politically sensitive provenance — that context was never created at the item level. It exists, if at all, in collection-level guides that the API does not return, in institutional memory that the API cannot access, and in the professional judgment of reference archivists who are increasingly not in the room.
What this means for descriptive practice
The most important finding from this audit is not that archival context disappears when records become data. It is that different kinds of context survive at different rates, and that the gap between structural survival and interpretive survival is not uniform — it tracks, with uncomfortable precision, the history of descriptive investment in specific collections.
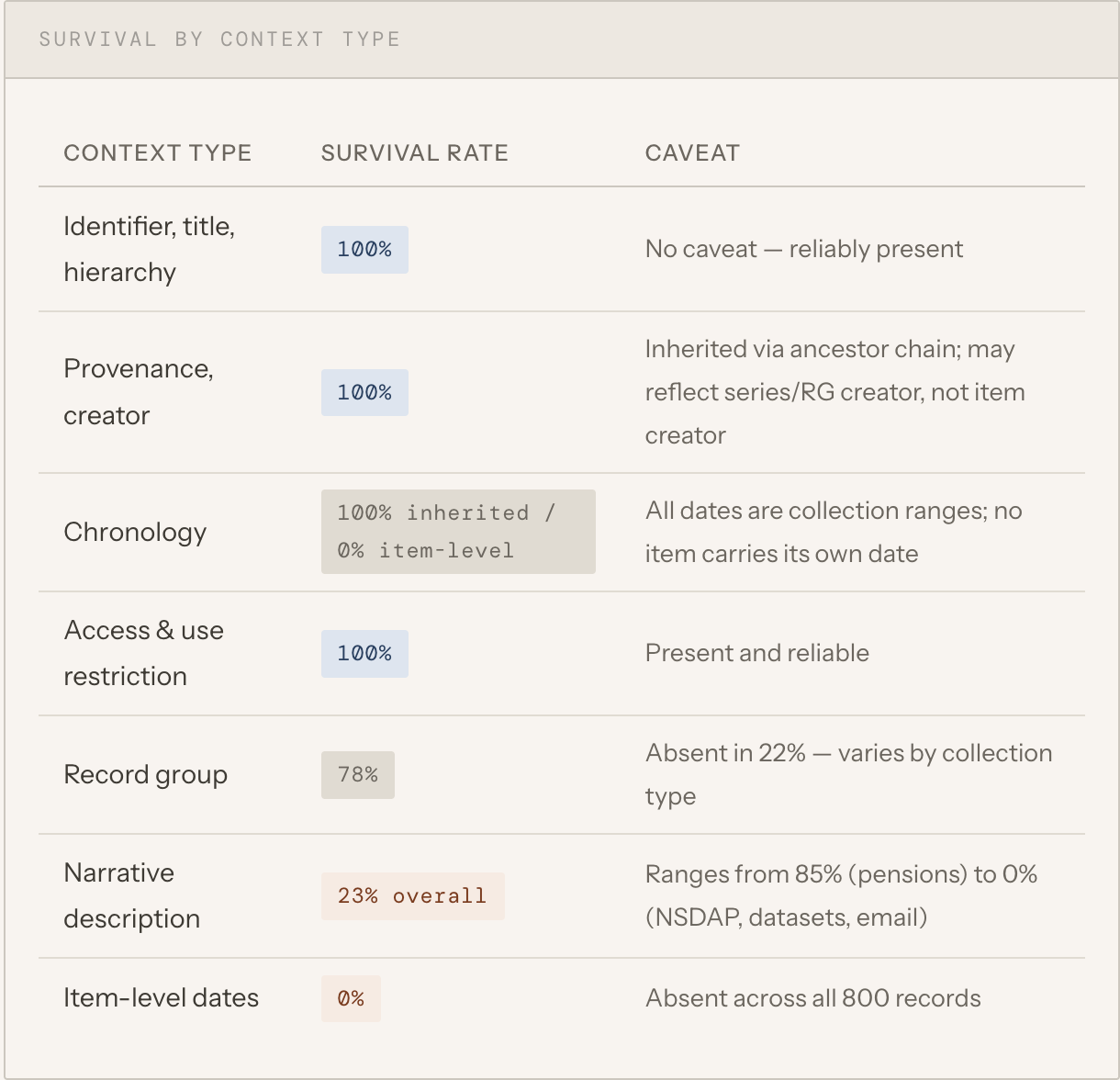
Provenance information, hierarchical placement, identifiers, and record-group relationships appear consistently. Narrative description is present for well-tended collections and absent for almost everything else. Item-level chronology — the kind of date information that allows a researcher to establish sequence within a series — is uniformly absent across the entire sample, regardless of how well described a collection is at other levels.
For decades, archivists have focused on ensuring that records survive. That concern remains essential. But the emergence of AI systems, retrieval platforms, and machine-mediated research introduces a different challenge. The question is no longer only whether records survive. It is whether the descriptive infrastructure surrounding records is detailed enough, specific enough, and present at the right level of granularity to support interpretation by systems that have no other way to understand what they are reading.
A machine that retrieves a pension file and finds a scope note can understand something about what it holds. A machine that retrieves an NSDAP membership record and finds only a hierarchical path and a record group number knows, structurally, where the record belongs. It does not know what the record is for, what dangers attach to misreading it, or what the archivist who processed the collection understood that is not written down anywhere the API can reach.
That gap is not the API’s fault. The API is doing its job. The question is whether archivists, collectively, are doing their work at the granularity level that the machine-mediated archive now requires.
This is a gross oversimplification, but hear me out, because I think I have the essence boiled down: the AI is functioning as a conversational finding aid. If we are honest, that is what information is present AND absent from the finding aid. In either case, you cannot really get the full context about records unless you ask the archivist.
Also, this demonstrates why precision, thoroughness, and description-egalitarianism are important. If we do not describe all collections to at least a lower level than collection-level, then they will not be discoverable in a traditional finding aid OR an AI tool.
This is an AMAZING exploration.